|
Pseudocode
AlphaZero
Backpropagation
Conjugate Gradient Method
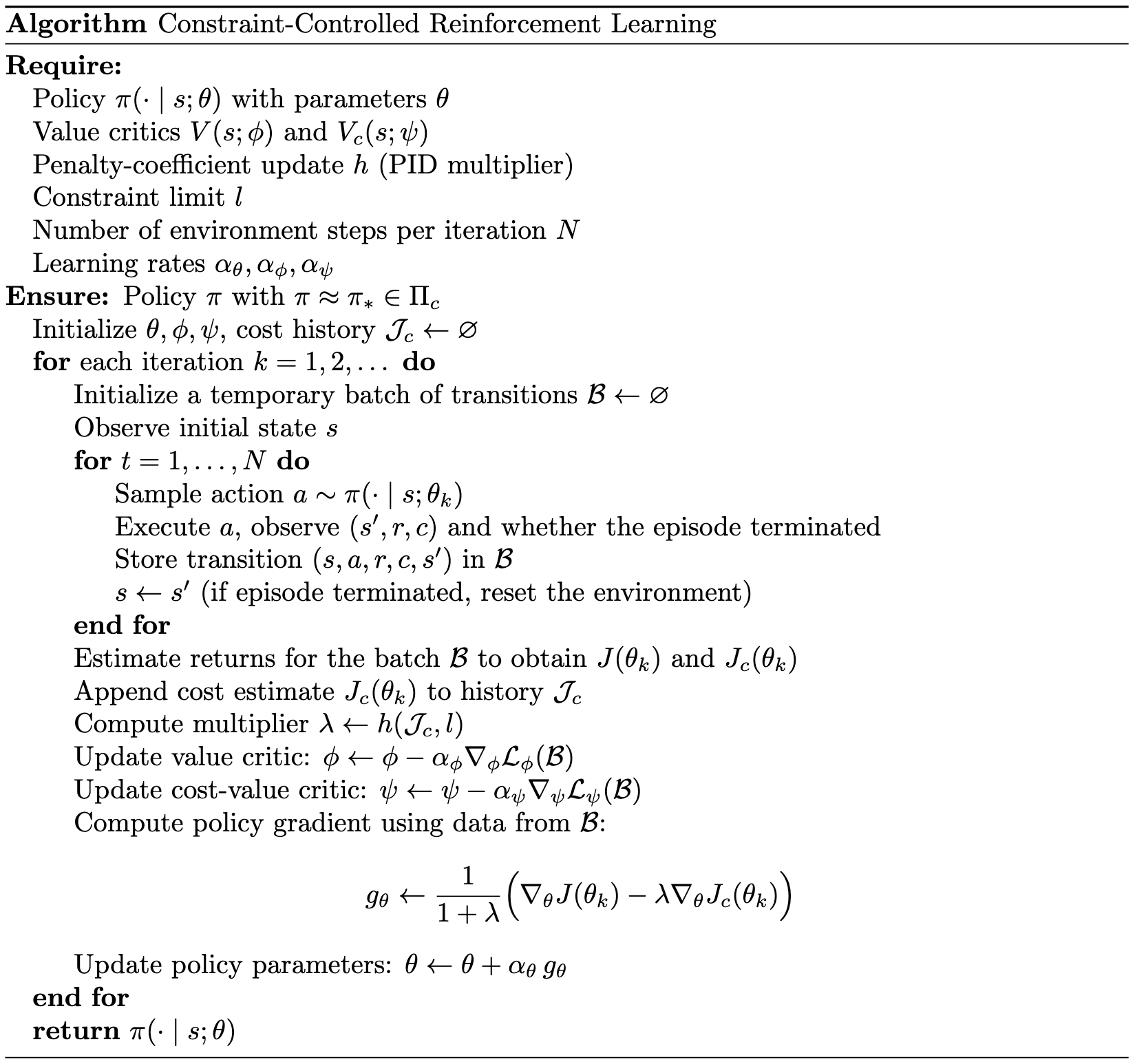
Constraint-Controlled Reinforcement Learning
Cross Entropy Method
Deep Q-learning
Deep Deterministic policy gradients (DDPG)
Deterministic policy gradients
Double Deep Q-learning
Dual Gradient Descent
Every-visit Monte Carlo prediction
First-visit Monte Carlo prediction
Implicit Q-Learning
\(n\)-step TD
One-step actor-critic
Policy iteration
PPO
Q-learning
REINFORCE
SARSA
Semi-gradient SARSA (episodic)
Semi-gradient TD(0)
Soft Actor-Critic (SAC)
Successor Features with Generalized Policy Improvement
Twin Delayed Deep Deterministic Policy Gradients (TD3)
TD(0)
TD(\(\lambda\))
Trust Region Policy Optimization (TRPO)
Value iteration
|